Что такое gpu в компьютере. GPU vs CPU: Почему для анализа финансовых данных применяют графические процессоры
Немецкого исследователя об использовании вычислений GPU в эконофизике и статистической физике, в том числе для осуществления анализа информации на фондовом рынке. Мы представляем вашему вниманию основные тезисы этого материала.
Примечание: Статья в журнале датирована 2011 годом, с тех пор появились новые модели GPU-устройств, однако общие подходы к использованию этого инструмента в инфраструктуре для онлайн-трейдинга остались неизменными
Требования к вычислительным мощностям растут в различных сферах. Одна из них - финансовый анализ, который необходим для успешной торговли на фондовом рынке, особенно средствами HFT. Для того, чтобы принять решение о покупке или продаже акций, алгоритм должен проанализировать серьезный объём входных данных - информация о транзакциях и их параметрах, текущих котировках и трендах изменения цены и т.д.
Время, которое пройдет от создания заявки на покупку или продажу до получения ответа о ее успешныом выполнеии от биржевого сервера называется раундтрипом (round-trip, RTT). Участники рынка всеми силами стремятся снизить это время, в частности для этого используются технологии прямого доступа на биржу, а серверы с торговым софтом располагаются на колокации рядом с торговым движком бирж.
Однако технологические возможности по сокращению раундтрипа ограничены, и после их исчерпания перед трейдерами встает вопрос о том, как еще можно ускорить торговые операции. Для этого применяются новые подходы к построению инфраструктуры для онлайн-трейдинга. В частности используются FPGA и GPU. Об ускорении HFT-трейдинга с помощью «программируемого железа» мы писали ранее, сегодня речь пойдет о том, как для этого можно применять графические процессоры.
Что такое GPU
Архитектура современных графических карт строится на основе масштабируемого массива потоковых мультипроцессоров. Один такой мультипроцессор содержит восемь скалярных процессорных ядер, многопоточный модуль инструкций, разделяемую память, расположенную на чипе (on-chip).Когда программа на C, использующая расширения CUDA, вызывает ядро GPU, копии этого ядра или потоки, нумеруются и распределяются на доступные мультипроцессоры, где уже начинается их выполнение. Для такой нумерации и распределения сеть ядра подразделяется на блоки, каждый из которых делится на различные потоки. Потоки в таких блоках выполняются одновременно на доступных мультипроцессорах. Для управления большим количеством потоков используется модуль SIMT (single-instruction multiple-thread). Этот модуль группирует их в «пачки» по 32 потока. Такие группы исполняются на том же мультипроцессоре.
Анализ финансовых данных на GPU
В финансовом анализе применяется множество мер и показателей, расчет которых требует серьезных вычислительных мощностей. Ниже мы перечислим некоторые из них и сравним быстродействие при их обработке, показанное «обычным» процессоромо Intel Core 2 Quad CPU (Q6700) c тактовой частотой 2,66 ГГц и размером кэша 4096 килобайт, а также популярных графических карт.Экспонента Херста
Мера, называемая экспонентной Херста, используется в анализе временных рядов. Эта величина уменьшается в том случае, если задержка между двумя одинаковыми парами значений во временном ряду увеличивается. Изначально это понятие применялось в гидрологии для определения размеров плотины на реке Нил в условиях непредсказуемых дождей и засух.Впоследствии показатель Херста начали применять в экономике, в частности, в техническом анализе для предсказания трендов движения ценовых рядов. Ниже представлено сравнение быстродействия вычисления показателя Херста на CPU и GPU (показатель «ускорения» β = общее время выисления на CPU / общее время вычисления на GPU GeForce 8800 GT):

Модель Изинга и метод Монте-Карло
Еще одним инструментом, перекочевавшим в сферу финансов на этот раз из физики, является модель Изинга . Эта математическая модель статистической физики предназначена для описания намагничивания материала.Каждой вершине кристаллической решётки (рассматриваются не только трёхмерные, но и одно- и двумерные вариации) сопоставляется число, называемое спином и равное +1 или −1 («поле вверх»/«поле вниз»). Каждому из 2^N возможных вариантов расположения спинов (где N - число атомов решётки) приписывается энергия, получающаяся из попарного взаимодействия спинов соседних атомов. Далее для заданной температуры рассматривается распределение Гиббса - рассматривается его поведение при большом числе атомов N.
В некоторых моделях (например, при размерности > 1) наблюдается фазовый переход второго рода. Температура, при которой исчезают магнитные свойства материала, называется критической (точка Кюри). В ее окрестности ряд термодинамических характеристик расходится.
Изначально модель Изинга использовалась для понимания природы ферромагнетизма, однако позднее получила и более широкое распространение. В частности, она применяется для обобщений в социально-экономических системах. Например, обобщение модели Изинга определяет взаимодействие участников финансового рынка. Каждый из них обладает стратегией поведения, рациональность которой может быть ограничена. Решения о том, продавать или покупать акции и по какой цене, зависят от предыдущих решений человека и их результата, а также от действий других участников рынка.
Модель Изинга используется для моделирования взаимодействия между участниками рынка. Для реализации модели Изинга и имитационного моделирования используется метод Монте-Карло, который позволяет построить математическую модель для проекта с неопределенными значениями параметров.
Ниже представлено сравнение быстродействия моделирования на CPU и GPU (NVIDIA GeForce GTX 280):

Существуют реализации модели Изинга с использованием в ходе анализа различного количества спинов. Мультиспиновые реализации позволяет загружать несколько спинов параллельно.
Ускорение с помощью нескольких GPU
Для ускорения обработки данных также используются кластеры GPU-устройств - в данном случае исследователи собрали кластер из двух карточек Tesla C1060 GPU, коммуникация между которыми осуществлялась через Double Data Rate InfiniBand.В случае симуляции модели Изинга методом Монте-Карло результаты говорят о том, что производительность повышается практически линейно при добавлении большего количества GPU.

Заключение
Эксперименты показывают, что использование графических процессоров может приводить к существуенному повышению производительности финансового анализа. При этом выигрыш в скорости по сравнению с использованием архитектуры с CPU может достигать нескольких десятков раз. При этом добиться еще большего повышения производительности можно с помощью создания кластеров GPU - в таком случае она растет практически линейно.Изучая технические характеристики компьютера, вы можете встретить такой термин как GPU. Данный термин обычно не объясняется простыми словами, поэтому пользователи редко понимают, что конкретно он означает. Иногда под GPU пользователи понимают видеокарту, хотя это не совсем верно. На самом деле GPU является частью видеокарты, а не самой видеокартой. В этом материале мы подробно расскажем о том, что такое GPU в компьютере, а также как узнать свой GPU и его температуру.
Аббревиатура GPU расшифровывается как Graphics Processing Unit, что можно перевести как устройство для обработки графики. Фактически GPU именно этим и является это отдельный модуль компьютера, который отвечает за обработку графики. В компьютере GPU может быть выполнен как отдельный кремниевый чип, который распаян на материнской или собственной отдельной плате (видеокарте), либо как часть центрального процессора или чипсета (северный мост).
Как выглядит GPU в компьютере.
Если GPU выполнен в качестве отдельного чипа, то его обычно называет графическим процессором, а если GPU является частью центрального процессора или чипсета, то часто для его обозначения используется термин интегрированная графика или встроенная графика.
В некоторых случаях под термином GPU понимают видеокарту, что не совсем верно, поскольку GPU – это именно чип (графический процессор), который занимается обработкой графики, а видеокарта - это целое устройство ответственное за обработку графики. Видеокарта состоит из графического процессора, памяти, имеет собственную плату и BIOS.
Другими словами, GPU – это графический процессор, который представляет собой кремниевый чип, на отдельной плате (видеокарте). Также под GPU может пониматься модуль, встроенный в центральный процессор (основной чип компьютера). В обоих случаях GPU занимается обработкой графики.
В современных условиях GPU часто используется не только для обработки графики, но и для решения других задач, которые могут быть обработаны с помощью графического процессора более эффективно, чем с помощью центрального процессора. Например, GPU используют для кодирования видео, машинного обучения, научных расчетов.
Как узнать какой GPU в компьютере
Пользователи часто интересуются, какой GPU используется в их компьютере. При этом под термином GPU чаще всего понимают видеокарту. Это связано с тем, пользователи обычно имеют дело с видеокартой в целом, а не конкретно с GPU. Например, название видеокарты необходимо для установки подходящих драйверов и проверки минимальных требований компьютерных игр. В то время как название GPU пользователю практически никогда не требуется.

В результате должно открыться окно «Диспетчера устройств». Здесь в разделе «Видеоадаптеры» будет указано название видеокарты.
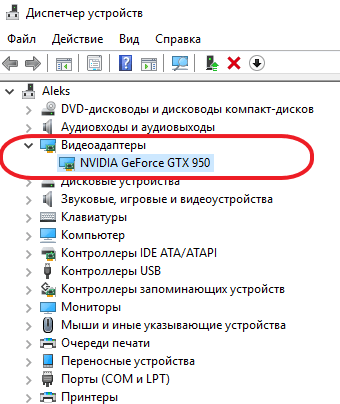
Но, вариант с диспетчером устройств не самый надежный. Если вы не установили драйверы для видеокарты, то система может ее не опознать и в диспетчере устройств не будет информации о ее названии. В таком случае лучше обратиться к сторонним программам. Например, можно установить программу , которая покажет всю возможную информацию об установленной видеокарте. Например, в GPU-Z название видеокарты можно узнать в строке «Name» в самом верху окна программы. На скриншоте внизу показано название видеокарты, это NVIDIA GTX GeForce 950.

Также в GPU-Z можно узнать название самого GPU (графического процессора). Например, на скриншоте внизу показано, что видеокарта NVIDIA GTX GeForce 950 построена на базе графического процессора GM206.

Температура GPU
GPU является один из самых горячих компонентов компьютера. Как и центральный процессор, GPU выделяет много тепла и его нужно эффективно отводить. Иначе графический процессор начнет перегреваться, что приведет к снижению производительности, сбоям в работе, перегрузкам компьютера и даже поломке.
Узнать температуру GPU можно с помощью специальных программ. Например, можно использовать , которую мы уже вспоминали. Если в программе GPU-Z перейти на вкладку «Sensors», то можно получить информацию о текучем состоянии видеокарты. Здесь будет указана частота GPU, его загрузка, температура и другие параметры.

Если вы хотите проверить не только температуру GPU, но и температуры других компонентов компьютера, то для этого удобно пользоваться программой . Данная программа отображает температуру, частоты, загрузку и другие параметры сразу для всех компонентов.

После проверки температуры часто возникает вопрос, . Точного ответа на этот вопрос нет, поскольку у разных GPU разный предел температур, которые они могут переносить без последствий. Но, в среднем нормальной температурой графического процессора является :
- до 55 °C в режиме простоя;
- до 80 °C под нагрузкой;
Если температура вашего GPU выходит за эти пределы, то это можно считать перегревом. В таком случае нужно улучшить охлаждение графического чипа, для того чтобы привести эти значения к норме.
Если нужно , то стоит начать с удаления пыли, которая скопилась на ее радиаторе. Если радиатор сильно забит пылью, то это может повышать температуру графического процессора на 5-10 градусов. Если простая чистка радиатора не помогает, то нужно заменить термопасту. В крайнем случае можно улучшить продуваемость корпуса компьютера, добавив несколько вентиляторов на вдув и выдув воздуха.
CPU и GPU очень похожи между собой. Они оба сделаны из миллионов транзисторов, способны совершать тысячи операций в секунду, поддаются . Но в чем разница между CPU и GPU ?
Что такое CPU?
CPU (Central Processing Unit) – это центральный процессор, другими словами – “мозг” компьютера. Это набор из нескольких миллионов транзисторов, которые могут выполнять сложные вычисления. Стандартный процессор имеет от одного до четырех ядер с тактовой частотой от 1 до 4 ГГц, хотя недавно .
CPU – достаточно мощное устройство, которое способно выполнять любые задачи на компьютере. Количество ядер и тактовая частота CPU это одни из ключевых
Что такое GPU?
GPU (Graphics Processing Unit) – это специализированный тип микропроцессора, который оптимизирован для отображения графики и решения специфичных задач. Тактовая частота GPU существенно ниже, чем в CPU, но обычно он имеет больше ядер.

В чем разница между CPU и GPU?
Графический процессор может совершать лишь часть из многих операций CPU, но делает он это с невероятной скоростью. GPU использует сотни ядер для расчетов в реальном времени, чтобы отображать тысячи пикселей на мониторе. Это позволяет плавно отображать сложную игровую графику.

Тем не менее, CPU являются более гибкими, чем GPU. Центральные процессоры имеют больший набор команд, так что они могут решать более широкий круг задач. CPU работают на более высоких максимальных частотах и могут управлять вводом и выводом всех компонентов компьютера. CPU способны работать с виртуальной памятью, которая нужна для современных операционных систем, а GPU – нет.
Немного об вычислениях на GPU
Несмотря на то, что графические процессоры являются лучшими для видео рендеринга, технически они способны сделать больше. Обработка графических данных это только один из видов повторяющихся и высоко параллельных задач. Другие задачи, такие как добыча Bitcoin или перебор паролей полагаются на те же типы больших наборов данных и математические операции. Вот почему многие люди используют GPU для “неграфических” целей.
Итог
Центральные и графические процессоры имеют схожие цели, но оптимизированы для разных вычислительных задач. В этом и разница между CPU и GPU. Для правильной и эффективной работы компьютер должен иметь оба типа микропроцессоров.
Время идет, процессоры становятся все мощнее и многоядернее. Видеокарты также наращивают количество вычислительных блоков и помимо создания 3D-изображения пытаются решать те задачи, которыми до сих пор занимались центральные процессоры. При этом разработчики видеокарт обещают значительное повышение производительности, что, в общем-то, подкрепляется цифрами. Но остается вопрос - на самом ли деле архитектура видеокарт лучше подходит для решения хорошо распараллеливаемых задач и потоковой обработки больших массивов данных? Если так, то зачем нам тогда многоядерные процессоры, может действительно стоит "переложить" нагрузку на видеокарты? Сегодня мы попытаемся ответить на вопрос - "кто кого поборет, кит или слон?", применительно к соревнованию CPU и GPU в части физических расчетов. Данный материал не претендует на полноту и всеохватность, более того - рассматриваемые здесь вопросы являются далеко не единственным примером "соревнования" CPU и GPU в области вычислений. Собственно, эти заметки и появились лишь в результате дискуссии с коллегами по поводу "кто сильнее, CPU или GPU". Не откладывая в долгий ящик, решено было проверить, а действительно - кто? Вы не поверите, но итог соревнования оказался не столь очевиден, и результаты удивили обе стороны. А почему так получилось, сейчас и увидим. В качестве тестового приложения мы решили взять 3DMark Vantage, а конкретно, один из входящих в пакет тестов - CPU Physics. Выбор, в общем-то, ничем особым не обусловлен, можно сказать - "что под руку попалось". Просто в 3DMark Vantage обычно мы тестируем видеокарты, а в него входит тест расчета "физики", который может выполнятся как на CPU, так и на видеоадаптерах NVIDIA. Вот давайте и посмотрим, кто считает "физику" быстрее.
Тестовое оборудование
Для сравнения мы взяли три процессора. Один из них уже довольно стар - Intel Core 2 Quad QX6850. Второй процессор более современный - AMD Phenom II X4 965. Третий еще современнее - AMD Athlon II X4 620. Конечно, надо было бы взять еще Core i7 или Core i5, но в это время они были заняты в других тестах. Впрочем, и трех имеющихся представителей "процессорного "лагеря будет вполне достаточно для получения качественных и количественных оценок.Что касается видеокарт, то мы использовали три следующие модели NVIDIA:
- GeForce 9500GT (32 унифицированных процессора)
- GeForce 9600GT (64 унифицированных процессора)
- GeForce GTX260 (216 унифицированных процессоров)
Тестирование
В качестве "удельной мощности" CPU или GPU мы будем рассматривать величину производительности в тесте 3DMark Vantage CPU Physics Test (которая измеряется в количестве кадров в секунду), поделенную на количество ядер или шейдерных блоков, а также частоту в мегагерцах. То есть, будем измерять "удельную мощность" в FPS/(МГц*количество вычислительных потоков). Собственно, для получения этой величины осталось измерить количество FPS в тесте при разных частотах процессоров и видеокарт, так как количество ядер CPU фиксировано, как и количество потоковых процессоров у видеокарт. Итак, приступим. Поскольку CPU до сих пор является "сердцем" компьютера, начнем именно с него. Мы решили немножко усложнить себе задачу и заодно выяснить, как масштабируется производительность CPU в данном тесте не только от частоты, но и от количества ядер. Ядра "отключались" путем задания соответствия на требуемое число ядер CPU для 3DMark Vantage в "Диспетчере задач". Данный метод неидеален, но для наших задач его вполне хватит. Кстати, несмотря на то, что процессор Intel Core 2 Quad QX6850 по сути состоит из двух ядер на одной подложке, какого либо влияния в данном тесте это не оказало. То есть, вариант, когда два ядра используют общий кэш объемом 4 Мб и случай, когда каждое из ядер использует кэш по 4 Мб, показали результаты, совпадающие в пределах погрешности. Ну а масштабирование по частоте осуществлялось путем изменения коэффициента умножения процессора в сторону понижения, прочие параметры системы оставались неизменными. Смотрим, что получилось.Как видите, с увеличением частоты производительность в тесте растет практически линейно. Теоретически, прямые линии должны начинаться от начала координат, поскольку при нулевой частоте CPU мы просто не получим никаких результатов, то есть нулевой FPS. Давайте проведем прямые линии от начала координат и проверим, насколько они совпадут с экспериментальными кривыми.
Получаются весьма занятные результаты. Результаты Intel Core 2 Quad QX6850 практически идеально ложатся на прямые линии (за исключением случая для трех активных ядер, что может быть обусловлено как раз несимметричностью распределения кэш-памяти между ними в силу архитектуры). Результаты процессора AMD Athlon II X4 620 также хорошо ложатся на линию, проходящую через начало координат. А вот для AMD Phenom II X4 965 все несколько сложнее. Если проводить прямую от начала координат через точку, соответствующую минимальной частоте, то следующие точки отклоняются от этой прямой вниз (случай для одного и двух активных ядер). Если же проводить прямую через точки, соответствующие более высокой частоте CPU, то получается, что результаты на частоте 2000 МГц лежат сверху над прямой. Вероятно, такое поведение результатов можно объяснить наличием у AMD Phenom кэш-памяти третьего уровня. При частоте CPU равной 2000 МГц ядра и кэш-память L3 работают синхронно, поэтому результат максимален. При увеличении частоты ядер частота L3-кэш процессора остается неизменной, и он может вносить какие-то задержки, поэтому результаты "переходят" на прямую, коэффициент наклона которой ниже. Теперь давайте вычислим "удельную мощность" рассматриваемых процессоров в этом тесте. Напомним, что это по сути есть коэффициент наклона касательной, дополнительно разделенный на количество задействованных ядер CPU. Результаты приведены в таблице ниже.
| "Удельная мощность" CPU, FPS/(МГц*кол-во ядер) | |||
| Кол-во ядер | Core 2 Quad QX6850 | Phenom II X4 965 | Athlon II X4 620 |
| 1 | 0.001363 | 0.001467 | |
| 2 | 0.001252 | 0.001381 | |
| 3 | 0.001249 | 0.001331 | |
| 4 | 0.00124 | 0.001346 | 0.001348 |
Удивительно, но в при расчетах "физики" в 3DMark Vantage рассматриваемые процессоры AMD показывают чуть лучшие результаты, чем представитель архитектуры Intel Core 2 Quad. Теперь давайте посмотрим, какую "удельную мощность" продемонстрируют GPU производства NVIDIA. Поскольку видеопроцессор является довольно сложным устройством, возник вопрос - а как вообще эту "удельную мощность" считать? Поскольку вычислениями в основном занимаются шейдерные блоки, было решено строить графики результатов на основе именно этого параметра. Что касается частоты блоков ROP, то она выбиралась максимально возможной при данной частоте шейдеров. Как оказалось, минимальный коэффициент частоты шейдерных блоков по отношению к частоте ROP-блоков равен двум. Именно такое соотношение частот и сохранялось на протяжении всех тестов. Для этой части тестов использовался тестовый стенд на основе Core 2 Quad QX6850, рабочая частота процессора - 3600 МГц, все четыре ядра активны. Результаты показаны на графике ниже.
Как видите, в данном тесте по абсолютным показателям видеокарты значительно опережают центральные процессоры в производительности. Причем даже самая слабая из присутствующих модель на минимальных частотах оказывается быстрее четырехъядерного CPU с частотой 3600 МГц. Однако поведение линий результатов несколько отличается от того, что мы видели для центральных процессоров. Более подробно это видно на графике ниже.
На этом графике через точки, соответствующие минимальным рабочим частотам видеокарт, мы провели прямые линии. Как оказалось, они сходятся не в начале координат, а пересекают ось ординат на уровне примерно 20 FPS. Странно, не правда ли? Как оказалось, ничего странного нет, а поведение линий вполне закономерно. Для этого достаточно было посмотреть на загрузку CPU во время выполнения теста - она достигала 100% для каждого из ядер. Если вернуться к данным графика №1, то легко заметить, что результат теста на процессоре Intel Core 2 Quad QX6850 @ 3600 МГц как раз и составляет 18 FPS. Мы пробовали снижать частоту процессора и уменьшать количество активных ядер, и каждый раз уровень вертикального смещения линий результатов для GPU с хорошей точностью совпадал с производительностью центрального процессора в данном тесте. Что касается отклонения линий результатов от построенных прямых, то это объясняется проще - начиная с определенного момента часть шейдерных блоков, по всей видимости, загружены не полностью. Возможно, сказываются ограниченные возможности по распараллеливанию нагрузки самого теста, а может играют роль какие-то ограничения в архитектуре видеопроцессора. Как бы там ни было, давайте вычислим "удельную мощность" GPU, используя, как и прежде, коэффициент наклона построенных прямых, поделенный на количество потоковых процессоров. Полученные результаты отображены в таблице ниже. Также в ней указана "удельная мощность" Intel Core 2 Quad QX6850.
| "Удельная мощность" | Коэффициент "отставания" GPU от CPU |
|
| Intel Core 2 Quad QX6850 | 0.00124 | |
| 9500GT (32 shaders) | 0.00084 | 1.48 |
| 9600GT (64 shaders) | 0.00063 | 1.97 |
| GTX260 (216 shaders) | 0.00050 | 2.46 |
В это трудно поверить, но в тесте 3DMark Vantage CPU Physics Test "удельная мощность" довольно старого, по нынешним меркам, центрального процессора оказывается как минимум в полтора раза больше "удельной мощности" современных видеопроцессоров NVIDIA. Такой вот парадоксальный результат. Впрочем, мы вовсе не предлагаем отказаться от расчетов на GPU в пользу центральных процессоров. У GPU есть еще один козырь - большая производительность на ватт потребляемой мощности. Эти прикидки сделать несложно, поэтому оставим эту возможность читателям. Ну а если сравнить абсолютные результаты CPU и GPU, полученные в рамках данного тестирования, то современные процессоры еще не скоро до них дорастут. Впрочем, и отрицать успехи процессоростроения не стоит. Не так давно были опубликованы результаты тестирования разогнанного шестиядерного процессора Intel Core i9 Gulftown . Разогнанный до частоты 5892 МГц, этот процессор в тесте 3DMark Vantage CPU Physics Test показал результат 63,01 FPS. Если подсчитать "удельную мощность" новинки, то получаем величину 0.00178 FPS/(МГц*кол-во ядер), что в 1.44 раза больше "удельной мощности" процессора Core 2 Quad QX6850. То есть 44% прибавки достигаются за счет преимуществ архитектуры Core i9 и технологии HyperThreading. И хотя прямого противостояния CPU и GPU по всему фронту решаемых задач пока не наблюдается, кто знает, где именно между ними развернется жестокая конкуренция. Стоит упомянуть AMD Radeon HD 5870 , обладающий вычислительной мощностью 2,7 TFLOPS, а также Microsoft DirectX 11 с поддержкой технологии Compute Shader, позволяющей переложить расчеты на GPU. То ли еще будет...
Графические процессоры (graphics processing unit, GPU) - яркий пример того, как технология, спроектированная для задач графической обработки, распространилась на несвязанную область высокопроизводительных вычислений. Современные GPU являются сердцем множества сложнейших проектов в сфере машинного обучения и анализа данных. В нашей обзорной статье мы расскажем, как клиенты Selectel используют оборудование с GPU, и подумаем о будущем науки о данных и вычислительных устройств вместе с преподавателями Школы анализа данных Яндекс.
Графические процессоры за последние десять лет сильно изменились. Помимо колоссального прироста производительности, произошло разделение устройств по типу использования. Так, в отдельное направление выделяются видеокарты для домашних игровых систем и установок виртуальной реальности. Появляются мощные узкоспециализированные устройства: для серверных систем одним из ведущих ускорителей является NVIDIA Tesla P100 , разработанный именно для промышленного использования в дата-центрах. Помимо GPU активно ведутся исследования в сфере создания нового типа процессоров, имитирующих работу головного мозга. Примером может служить однокристальная платформа Kirin 970 с собственным нейроморфным процессором для задач, связанных с нейронными сетями и распознаванием образов.
Подобная ситуация заставляет задуматься над следующими вопросами:
- Почему сфера анализа данных и машинного обучения стала такой популярной?
- Как графические процессоры стали доминировать на рынке оборудования для интенсивной работы с данными?
- Какие исследования в области анализа данных будут наиболее перспективными в ближайшем будущем?
Попробуем разобраться с этими вопросами по порядку, начиная с первых простых видеопроцессоров и заканчивая современными высокопроизводительными устройствами.
Эпоха GPU
Для начала вспомним, что же такое GPU. Graphics Processing Unit — это графический процессор широко используемый в настольных и серверных системах. Отличительной особенностью этого устройства является ориентированность на массовые параллельные вычисления. В отличие от графических процессоров архитектура другого вычислительного модуля CPU (Central Processor Unit) предназначена для последовательной обработки данных. Если количество ядер в обычном CPU измеряется десятками, то в GPU их счет идет на тысячи, что накладывает ограничения на типы выполняемых команд, однако обеспечивает высокую вычислительную производительность в задачах, включающих параллелизм.
Первые шаги
Развитие видеопроцессоров на ранних этапах было тесно связано с нарастающей потребностью в отдельном вычислительном устройстве для обработки двух и трехмерной графики. До появления отдельных схем видеоконтроллеров в 70-х годах вывод изображения осуществлялся через использование дискретной логики, что сказывалось на увеличенном энергопотреблении и больших размерах печатных плат. Специализированные микросхемы позволили выделить разработку устройств, предназначенных для работы с графикой, в отдельное направление.
Следующим революционным событием стало появление нового класса более сложных и многофункциональных устройств — видеопроцессоров. В 1996 году компания 3dfx Interactive выпустила чипсет Voodoo Graphics, который быстро занял 85% рынка специализированных видеоустройств и стал лидером в области 3D графики того времени. После серии неудачных решений менеджмента компании, среди которых была покупка производителя видеокарт STB, 3dfx уступила первенство NVIDIA и ATI (позднее AMD), а в 2002 объявила о своем банкротстве.
Общие вычисления на GPU
В 2006 году NVIDIA объявила о выпуске линейки продуктов GeForce 8 series, которая положила начало новому классу устройств, предназначенных для общих вычислений на графических процессорах (GPGPU). В ходе разработки NVIDIA пришла к пониманию, что большее число ядер, работающих на меньшей частоте, более эффективны для параллельных нагрузок, чем малое число более производительных ядер. Видеопроцессоры нового поколения обеспечили поддержку параллельных вычислений не только для обработки видеопотоков, но также для проблем, связанных с машинным обучением, линейной алгеброй, статистикой и другими научными или коммерческими задачами.

Признанный лидер
Различия в изначальной постановке задач перед CPU и GPU привели к значительным расхождениям в архитектуре устройств - высокая частота против многоядерности. Для графических процессоров это заложило вычислительный потенциал, который в полной мере реализуется в настоящее время. Видеопроцессоры с внушительным количеством более слабых вычислительных ядер отлично справляются с параллельными вычислениями. Центральный же процессор, исторически спроектированный для работы с последовательными задачами, остается лучшим в своей области.
Для примера сравним значения в производительности центрального и графического процессора на выполнении распространенной задачи в нейронных сетях - перемножении матриц высокого порядка. Выберем следующие устройства для тестирования:
- CPU. Intel Xeon E5-2680 v4 — 28 потоков с HyperThreading, 2.4 GHZ;
- GPU. NVIDIA GTX 1080 — 2560 CUDA Cores, 1607 Mhz, 8GB GDDR5X.
Используем пример вычисления перемножения матриц на CPU и GPU в Jupyter Notebook:

В коде выше мы измеряем время, которое потребовалось на вычисление матриц одинакового порядка на центральном или графическом процессоре («Время выполнения»). Данные можно представить в виде графика, на котором горизонтальная ось отображает порядок перемножаемых матриц, а вертикальная - Время выполнения в секундах:

Линия графика, выделенная оранжевым, показывает время, которое требуется для создания данных в обычном ОЗУ, передачу их в память GPU и последующие вычисления. Зеленая линия показывает время, которое требуется на вычисление данных, которые были сгенерированы уже в памяти видеокарты (без передачи из ОЗУ). Синяя отображает время подсчета на центральном процессоре. Матрицы порядка менее 1000 элементов перемножаются на GPU и CPU почти за одинаковое время. Разница в производительности хорошо проявляется с матрицами размерами более 2000 на 2000, когда время вычислений на CPU подскакивает до 1 секунды, а GPU остается близким к нулю.
Более сложные и практические задачи эффективнее решаются на устройстве с графическими процессорами, чем без них. Поскольку проблемы, которые решают наши клиенты на оборудовании с GPU, очень разнообразны, мы решили выяснить, какие самые популярные сценарии использования существуют.
Кому в Selectel жить хорошо с GPU?
Первый вариант, который сразу приходит на ум и оказывается правильной догадкой — это майнинг, однако любопытно отметить, что некоторые применяют его как вспомогательный способ загрузить оборудование на «максимум». В случае аренды выделенного сервера с видеокартами, время свободное от рабочих нагрузок используется для добычи криптовалют, не требующих специализированных установок (ферм) для своего получения.
Ставшие уже в какой-то степени классическими, задачи, связанные с графической обработкой и рендерингом, неизменно находят свое место на серверах Selectel с графическими ускорителями. Использование высокопроизводительного оборудования для таких задач позволяет получить более эффективное решение, чем организация выделенных рабочих мест с видеокартами.
В ходе разговора с нашими клиентами мы также познакомились с представителями Школы анализа данных Яндекс, которая использует мощности Selectel для организации тестовых учебных сред. Мы решили узнать побольше о том, чем занимаются студенты и преподаватели, какие направления машинного обучения сейчас популярны и какое будущее ожидает индустрию, после того как молодые специалисты пополнят ряды сотрудников ведущих организаций или запустят свои стартапы.
Наука о данных
Пожалуй, среди наших читателей не найдется тех, кто не слышал бы словосочетания «нейронные сети» или «машинное обучение». Отбросив маркетинговые вариации на тему этих слов, получается сухой остаток в виде зарождающейся и перспективной науки о данных.
Современный подход к работе с данными включает в себя несколько основных направлений:
- Большие данные (Big Data). Основная проблема в данной сфере - колоссальный объем информации, который не может быть обработан на единственном сервере. С точки зрения инфраструктурного обеспечения, требуется решать задачи создания кластерных систем, масштабируемости, отказоустойчивости, и распределенного хранения данных;
- Ресурсоемкие задачи (Машинное обучение, глубокое обучение и другие). В этом случае поднимается вопрос использования высокопроизводительных вычислений, требующих большого количества ОЗУ и процессорных ресурсов. В таких задачах активно используются системы с графическими ускорителями.
Граница между данными направления постепенно стирается: основные инструменты для работы с большими данным (Hadoop, Spark) внедряют поддержку вычислений на GPU, а задачи машинного обучения охватывают новые сферы и требуют бо́льших объемов данных. Разобраться подробнее нам помогут преподаватели и студенты Школы анализа данных.

Трудно переоценить важность грамотной работы с данными и уместного внедрения продвинутых аналитических инструментов. Речь идёт даже не о больших данных, их «озерах» или «реках», а именно об интеллектуальном взаимодействии с информацией. Происходящее сейчас представляет собой уникальную ситуацию: мы можем собирать самую разнообразную информацию и использовать продвинутые инструменты и сервисы для глубокого анализа. Бизнес внедряет подобные технологии не только для получения продвинутой аналитики, но и для создания уникального продукта в любой отрасли. Именно последний пункт во многом формирует и стимулирует рост индустрии анализа данных.
Новое направление
Повсюду нас окружает информация: от логов интернет-компаний и банковских операций до показаний в экспериментах на Большом адронном коллайдере. Умение работать с этими данными может принести миллионные прибыли и дать ответы на фундаментальные вопросы о строении Вселенной. Поэтому анализ данных стал отдельным направлением исследований среди бизнес и научного сообщества.
Школа анализа данных готовит лучших профильных специалистов и ученых, которые в будущем станут основным источником научных и индустриальных разработок в данной сфере. Развитие отрасли сказывается и на нас как на инфраструктурном провайдере - все больше клиентов запрашивают конфигурации серверов для задач анализа данных.
От специфики задач, стоящих перед нашими клиентами, зависит то, какое оборудование мы должны предлагать заказчикам и в каком направлении следует развивать нашу продуктовую линейку. Совместно со Станиславом Федотовым и Олегом Ивченко мы опросили студентов и преподавателей Школы анализа данных и выяснили, какие технологии они используют для решения практических задач.

Технологии анализа данных
За время обучения слушатели от основ (базовой высшей математики, алгоритмов и программирования) доходят до самых передовых областей машинного обучения. Мы собирали информацию по тем, в которых используются серверы с GPU:
- Глубинное обучение;
- Обучение с подкреплением;
- Компьютерное зрение;
- Автоматическая обработка текстов.
Студенты используют специализированные инструменты в своих учебных заданиях и исследованиях. Некоторые библиотеки предназначены для приведения данных к необходимому виду, другие предназначены для работы с конкретным типом информации, например, текстом или изображениями. Глубинное обучение - одна из самых сложных областей в анализе данных, которая активно использует нейронные сети. Мы решили узнать, какие именно фреймворки преподаватели и студенты применяют для работы с нейронными сетями.

Представленные инструменты обладают разной поддержкой от создателей, но тем не менее, продолжают активно использоваться в учебных и рабочих целях. Многие из них требуют производительного оборудования для обработки задач в адекватные сроки.
Дальнейшее развитие и проекты
Как и любая наука, направление анализа данных будет изменяться. Опыт, который получают студенты сегодня, несомненно войдет в основу будущих разработок. Поэтому отдельно стоит отметить высокую практическую направленность программы - некоторые студенты во время учебы или после начинают стажироваться в Яндексе и применять свои знания уже на реальных сервисах и службах (поиск, компьютерное зрение, распознавание речи и другие).
О будущем анализа данных мы поговорили с преподавателями Школы анализа данных, которые поделились с нами своим видением развития науки о данных.
По мнению Влада Шахуро , преподавателя курса «Анализ изображений и видео», самые интересные задачи в компьютерном зрении - обеспечение безопасности в местах массового скопления людей, управление беспилотным автомобилем и создание приложение с использованием дополненной реальности. Для решения этих задач необходимо уметь качественно анализировать видеоданные и развивать в первую очередь алгоритмы детектирования и слежения за объектами, распознавания человека по лицу и трехмерной реконструкции наблюдаемой сцены. Преподаватель Виктор Лемпицкий , ведущий курс «Глубинное обучение», отдельно выделяет в своем направлении автокодировщики, а также генеративные и состязательные сети.
Один из наставников Школы анализа данных делится своим мнением касательно распространения и начала массового использования машинного обучения:
«Машинное обучение из удела немногих одержимых исследователей превращается в ещё один инструмент рядового разработчика. Раньше (например в 2012) люди писали низкоуровневый код для обучения сверточных сетей на паре видеокарт. Сейчас, кто угодно может за считанные часы:
- скачать веса уже обученной нейросети (например, в keras);
- сделать с ее помощью решение для своей задачи (fine-tuning, zero-shot learning);
- встроить её в свой веб-сайт или мобильное приложение (tensorflow / caffe 2).
Многие большие компании и стартапы уже выиграли на такой стратегии (например, Prisma), но еще больше задач только предстоит открыть и решить. И, быть может, вся эта история с машинным/глубинным обучением когда-нибудь станет такой же обыденностью, как сейчас python или excel»
Точно предсказать технологию будущего сегодня не сможет никто, но когда есть определенный вектор движения можно понимать, что следует изучать уже сейчас. А возможностей для этого в современном мире — огромное множество.
Возможности для новичков
Изучение анализа данных ограничивается высокими требованиями к обучающимся: обширные познания в области математики и алгоритмики, умение программировать. По-настоящему серьезные задачи машинного обучения требуют уже наличия специализированного оборудования. А для желающих побольше узнать о теоретической составляющей науки о данных Школой анализа данных совместно с Высшей Школой Экономики был запущен онлайн курс « ».
Вместо заключения
Рост рынка графических процессоров обеспечивается возрастающим интересом к возможностям таких устройств. GPU применяется в домашних игровых системах, задачах рендеринга и видеообработки, а также там, где требуются общие высокопроизводительные вычисления. Практическое применение задач интеллектуального анализа данных будет проникать все глубже в нашу повседневную жизнь. И выполнение подобных программ наиболее эффективно осуществляется именно с помощью GPU.
Мы благодарим наших клиентов, а также преподавателей и студентов Школы анализа данных за совместную подготовку материала, и приглашаем наших читателей познакомиться с ними поближе .
А опытным и искушенным в сфере машинного обучения, анализа данных и не только мы предлагаем посмотреть от Selectel по аренде серверного оборудования с графическми ускорителями: от простых GTX 1080 до Tesla P100 и K80 для самых требовательных задач.






